Introduction
TabFSBench is a benchmarking tool for feature shifts in tabular data in open-environment scenarios. It aims to analyse the performance and robustness of a model in feature shifts.
TabFSBench offers the following advantages:
- Various Models: Tree-based models, deep-learning models, LLMs and tabular LLMs.
- Diverse Experiments: Single shift, most/least-revelant shift and random shift.
- Exportable Datasets: Be able to export the feature-shift version of the given dataset.
- Addable Components: Supports to add new datasets and models, and export the given dataset under the specific experiment.
Datasets
Datasets in TabFSBench. #Numerical means numerical features. #Categorical means categorical features.
| Tasks | Dataset | #Samples | #Numerical | #Categorical | #Labels | Link |
|---|---|---|---|---|---|---|
| Binary Classification | credit | 1,000 | 7 | 13 | 2 | https://www.openml.org/search?type=data&sort=runs&id=31&status=active |
| electricity | 45,312 | 8 | 0 | 2 | https://www.kaggle.com/datasets/vstacknocopyright/electricity | |
| heart | 918 | 6 | 5 | 2 | https://www.kaggle.com/datasets/fedesoriano/heart-failure-prediction | |
| MiniBooNE | 72,998 | 50 | 0 | 2 | https://www.kaggle.com/datasets/alexanderliapatis/miniboone | |
| Multi-Class Classification | Iris | 150 | 4 | 0 | 3 | https://www.kaggle.com/datasets/uciml/iris |
| penguins | 345 | 4 | 2 | 3 | https://www.kaggle.com/datasets/youssefaboelwafa/clustering-penguins-species | |
| eye_movements | 10,936 | 27 | 0 | 4 | https://www.kaggle.com/datasets/vinnyr12/eye-movements | |
| jannis | 83,733 | 54 | 0 | 4 | https://www.openml.org/search?type=data&status=active&id=45021 | |
| Regression | abalone | 4,178 | 7 | 1 | \ | https://www.kaggle.com/datasets/rodolfomendes/abalone-dataset |
| bike | 10,886 | 6 | 3 | \ | https://www.kaggle.com/datasets/abdullapathan/bikesharingdemand | |
| concrete | 1,031 | 8 | 0 | \ | https://www.kaggle.com/datasets/maajdl/yeh-concret-data | |
| laptop | 1,275 | 8 | 14 | \ | https://www.kaggle.com/datasets/owm4096/laptop-prices |
Models
TabFSBench is possible to test three kinds of models’ performance directly, including tree-based models, deep learning models and tabular LLMs. For LLMs, TabFSBnech provides text files(.json) about the given dataset that can be used directly for LLM to finetune.
Tree-based models
- CatBoost: A powerful boosting-based model designed for efficient handling of categorical features.
- LightGBM: A machine-learning model based on the Boosting algorithm.
- XGBoost: A machine-learning model incrementally building multiple decision trees by optimizing the loss function.
Deep learning models
We use LAMDA-TALENT to evaluate deep-learning models. You can get details from LAMDA-TALENT.
- MLP: A multi-layer neural network, which is implemented according to RTDL.
- ResNet: A DNN that uses skip connections across many layers, which is implemented according to RTDL.
- SNN: An MLP-like architecture utilizing the SELU activation, which facilitates the training of deeper neural networks.
- DANets: A neural network designed to enhance tabular data processing by grouping correlated features and reducing computational complexity.
- TabCaps: A capsule network that encapsulates all feature values of a record into vectorial features.
- DCNv2: Consists of an MLP-like module combined with a feature crossing module, which includes both linear layers and multiplications.
- NODE: A tree-mimic method that generalizes oblivious decision trees, combining gradient-based optimization with hierarchical representation learning.
- GrowNet: A gradient boosting framework that uses shallow neural networks as weak learners.
- TabNet: A tree-mimic method using sequential attention for feature selection, offering interpretability and self-supervised learning capabilities.
- TabR: A deep learning model that integrates a KNN component to enhance tabular data predictions through an efficient attention-like mechanism.
- ModernNCA: A deep tabular model inspired by traditional Neighbor Component Analysis, which makes predictions based on the relationships with neighbors in a learned embedding space.
- AutoInt: A token-based method that uses a multi-head self-attentive neural network to automatically learn high-order feature interactions.
- Saint: A token-based method that leverages row and column attention mechanisms for tabular data.
- TabTransformer: A token-based method that enhances tabular data modeling by transforming categorical features into contextual embeddings.
- FT-Transformer: A token-based method which transforms features to embeddings and applies a series of attention-based transformations to the embeddings.
- TANGOS: A regularization-based method for tabular data that uses gradient attributions to encourage neuron specialization and orthogonalization.
- SwitchTab: A self-supervised method tailored for tabular data that improves representation learning through an asymmetric encoder-decoder framework. Following the original paper, our toolkit uses a supervised learning form, optimizing both reconstruction and supervised loss in each epoch.
- TabPFN: A general model which involves the use of pre-trained deep neural networks that can be directly applied to any tabular task. TabFSBench uses the first version of TabPFN and supports to evaluate TabPFNv2 by updating the version.
LLMs
- Llama3-8B: Llama3-8B is released by Meta AI in April 2024.
- Due to memory limitations, TabFSBench only provides json files for LLM fine-tuning and testing (
datasetname_train.json / datasetname_test_i.json, i means the degree of feature shifts), asking users to use LLM locally. - TabFSBench provides the context of Credit Dataset. Users can rewrite background, features_information, declaration and question of
llm()in./model/utils.py.
- Due to memory limitations, TabFSBench only provides json files for LLM fine-tuning and testing (
Tabular LLMs
- TabLLM: A framework that leverages LLMs for efficient tabular data classification.
- UniPredict: A framework that firstly trains on multiple datasets to acquire a rich repository of prior knowledge. UniPredict-Light model that TabFSBench used is available at Google Drive. After downloading the model, place it in
./model/tabularLLM/files/unified/modelsand rename it tolight_state.pt.
Experimental Results
1. Most models have the limited applicability in feature-shift scenarios.
- Most models can’t handle feature shifts well.
- No Model Consistently Outperforms.
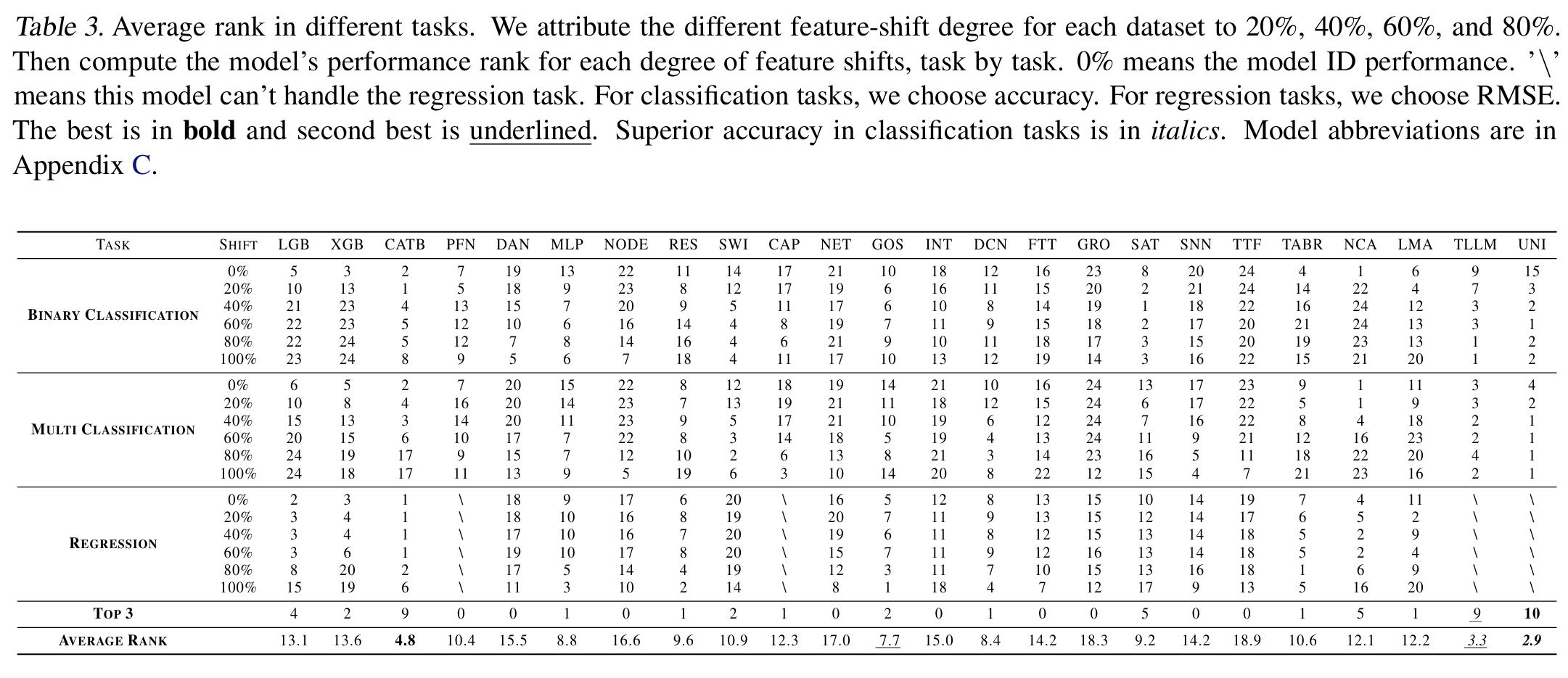
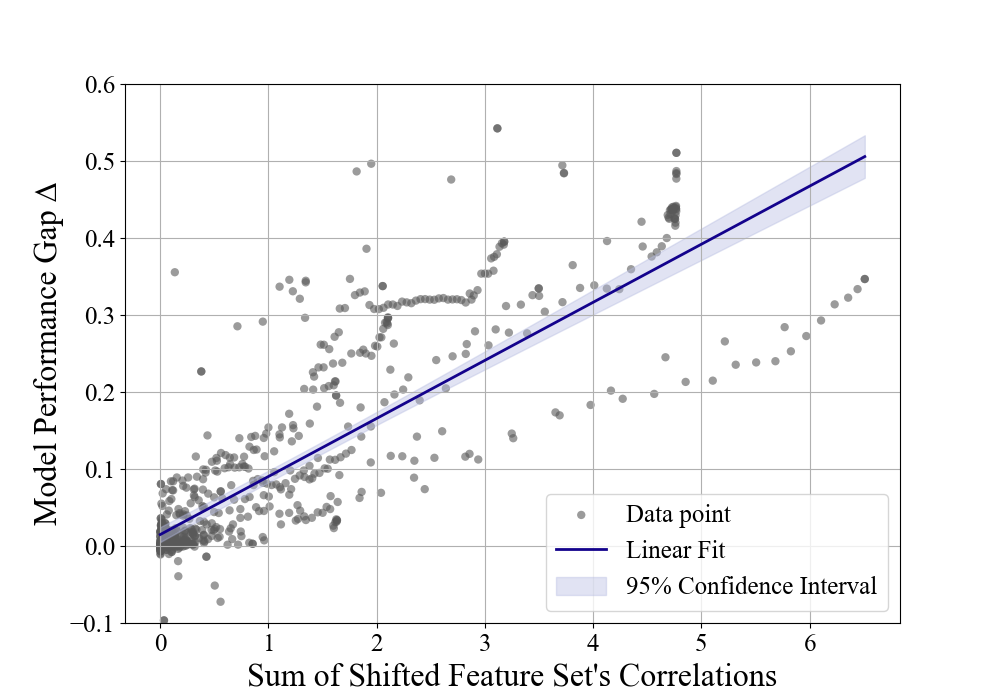
2. Shifted features’ importance has a linear trend with model performance degradation.
- Single strong correlated feature shifted causes greater model performance degradation.
- Shifted feature set’s correlations have a relationship with model performance degradation linearly.
We use performance gap to measure the model performance Gap $Delta$. Sum of shifted feature set’s correlations refers to the sum of Pearson correlation coefficients of shifted features. Notably, model performance Gap $Delta$ and sum of shifted feature set’s correlations demonstrate a strong correlation, with a Pearson correlation coefficient of $\rho$ = 0.7405.
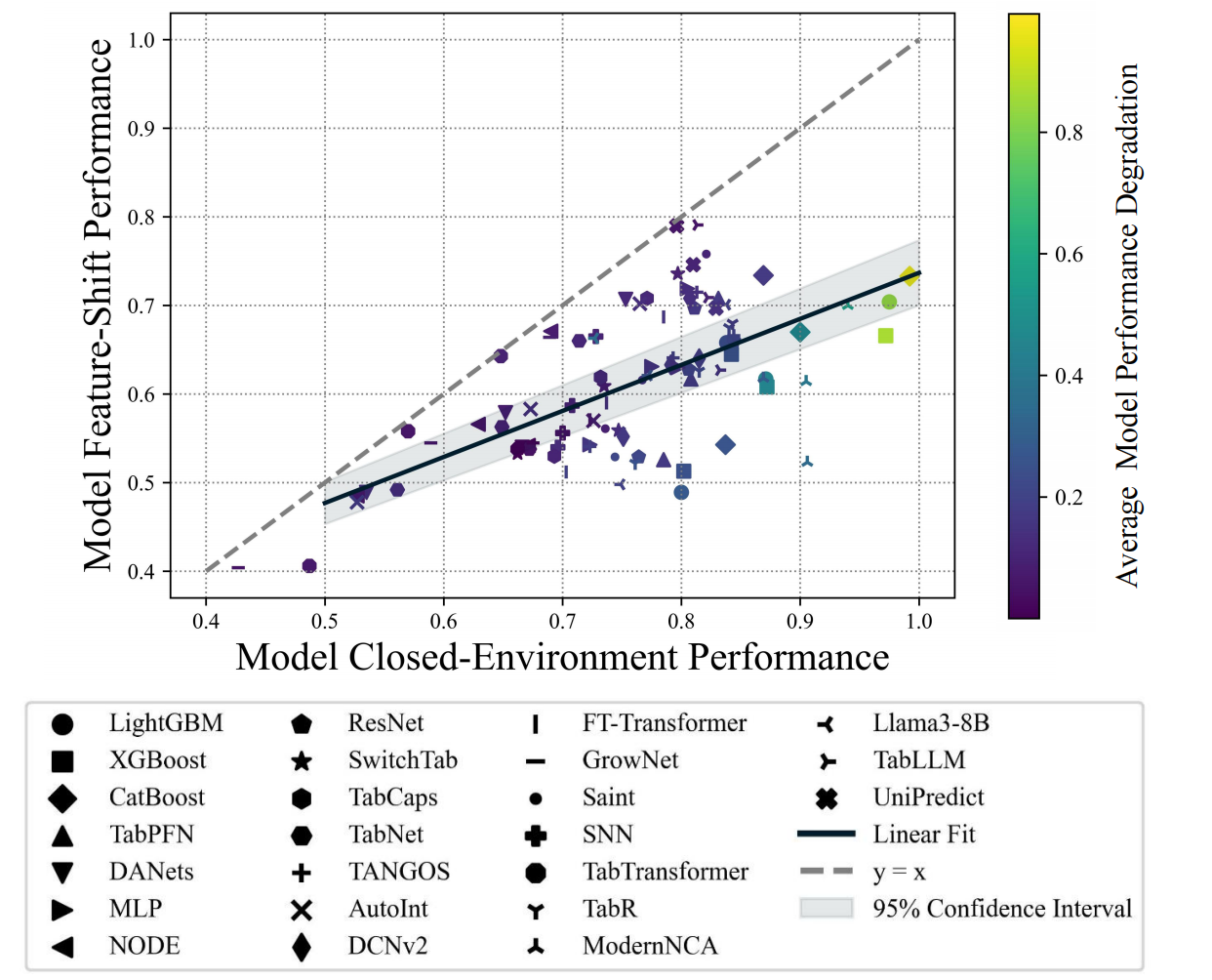
3. Model closed-environment performance correlates with feature-shift performance.
Model closed-environment performance vs. model feature-shift performance. Closed-environment means that the dataset does not have any degree of feature shift. Feature-shift means average model performance in all degrees of feature shifts.